Введение
Большинство пользователей Интернет сообщества начинают свой рабочий день с поисковых систем, где пытаются найти столь необходимую им информацию и решить свои проблемы. К сожалению, поисковые системы часто не способны точно и справедливо интерпретировать ресурсы. Как результат, на первых позициях поиска зачастую оказываются сайты "далекие" от решаемого вопроса. При этом ресурсы представляющие реальную пользу оказываются "за бортом" поиска.
Причина такого положения проста и кроется в технологии получения и представления результатов поисковыми системами. При этом надо понимать, что главная проблема заключается в отсутствии четких правил, доступных и открытых для всех желающих. Чем больше неопределенности в алгоритмах формирования поисковых индексов (некий черный ящик), тем меньше поисковые системы отражают процесс формирования реальной информации. И соответственно, тем меньше будет уровень доверия к результатам поиска поисковых систем.
Как это не парадоксально, но это вина не поисковых систем, поскольку они обязаны скрывать правила построения поисковых индексов. Это вина самой технологии при организации поиска. По своей сути технология поисковых систем направлена на пассивного пользователя. Необходимо зарегистрировать только сайт, дальше все сделает поисковый робот. Он просканирует ресурс страницу за страницей, пытаясь проанализировать содержание каждой из них. Трудоемкость пользователя минимальна, что позволяет использовать разные методики по "обману" поисковых роботов при низких затратах сил и средств. В такой схеме работы поисковым системам необходимо изменять алгоритмы и правила индексирования ресурсов и построения поискового индекса.
Конечно, большинство пользователей пользовались, пользуются, и будут пользоваться классическими поисковиками. Это просто, удобно и распространено. Это, как привычка, пользоваться поисковиками.
Общая информация о поисковых системах
Поисковая система - это программное обеспечение, предоставляющее доступ к коллекции слабоструктурированной информации. Ориентация на слабоструктурированные данные, т.е. данные, которые нельзя представить в виде реляционной таблицы, отличает поисковую систему от СУБД.
В данном определении поисковой системы подразумевается информация различного рода, т.е. текст, аудио, видео, изображения и т.п. Однако следует отметить, что именно текстовые данные идеально подходят для описания полной функциональности поисковой системы, т.к. алгоритмы поиска мультимедийной информации, прежде всего, основываются на алгоритмах поиска текста.
Основная задача поисковой системы - минимизировать время, затрачиваемое пользователем на поиск релевантной запросу информации. Релевантность - одно из самых субъективных и запутанных понятий в науке информационного поиска. Наиболее часто говорят о релевантности с точки зрения пользователя, и тогда ``релевантная запросу информация'' и ``нужная пользователю информация'' - одно и то же. Именно о такой релевантности мы говорим в данном разделе. Вопрос заключается в том, какую информацию пользователь посчитает нужной? В некоторых обстоятельствах релевантную информацию можно определить как всю информацию из базы, имеющую отношение к запросу. Так, например, если пользователю нужно узнать все о конкретной фирме, то он заинтересован в нахождении всех документов, в которых упоминается об этой фирме. В других обстоятельствах релевантная информация - это только та информация, которая достаточна для выполнения определенной задачи пользователя, например, поиска ответа на конкретный вопрос. Если в последнем случае в результатах поиска будет много избыточных данных, т.е. данных, которые имеют отношение к запросу, но не нужны для выполнения данной задачи, то выборка нужной/релевантной информации займет у пользователя дополнительное время.
Таким образом, традиционно к поисковой системе применяют две основные характеристики: точность и полнота, а точнее, их зависимость. Каждый раз, когда пользователь задает системе запрос, тем самым инициализируя поиск, все документы в коллекции поисковой системы делятся на четыре части.
Точность определяет один аспект поиска, а именно, насколько хорошо поисковая система способна минимизировать время, затрачиваемое пользователем на поиск релевантной данному запросу информации. В то время как полнота определяет другой аспект - насколько хорошо система способна найти релевантную данному запросу информацию. Можно подобрать оптимальный запрос(ы), когда каждый найденный документ будет релевантным, и каждый релевантный документ будет найден.
Поисковые системы при использовании Интернет играют очень важную роль. В Интернете сосредоточено такое количество информации, что ее поиск уже превращается в отдельную задачу и отнимает очень много времени. Поисковые серверы выдают на запрос тысячи ссылок вместо нескольких страниц, где действительно имеется нужная информация.
Пользователи всемирной сети Интернет, осознав преимущества, предоставляемые возможностью анализа пространственных данных, нуждаются в инструменте, позволяющем осуществлять быстрый и удобный поиск и доступ к цифровым снимкам местности и другой пространственной информации, сосредоточенной во многих правительственных, коммерческих и академических организациях.
Немного из истории…
Поисковая система (поисковый сервер, поисковая машина) – особый web-сайт, на котором пользователь по заданному запросу может получить ссылки на сайты, соответствующие этому запросу.
Работа поисковой машины, как правило, состоит из двух этапов. Первый - особая программа (поисковый робот) или человек собирает информацию с веб-страниц и индексирует их. Когда пользователь задает запрос, поиск идет по предварительно построенному индексу. Результатом поиска является так называемая поисковая выдача - список ссылок на документы (веб-страницы), соответствующие запросу.
Большая часть поисковых систем ищут информацию на сайтах Интернета, но также существуют поисковые машины, способные искать файлы на ftp-серверах, документы, а также информацию во внутренних сетях и прочая. В последнее время появился новый тип поисковых движков, основанных на технологии RSS.
Работа поисковой системы основана на работе «поискового движка». Основными критериями качества работы поисковой машины являются релевантность, полнота базы, учёт морфологии языка.
Наиболее популярными поисковыми машинами в России на сегодняшний день считаются Google, Yandex, и Rambler.
Первой поисковой машиной стал «Wandex», уже не существующий web-сайт, который создал Мэтью Грэйем из Массачусетского технологического института в 1993. чуть позднее появляется поисковая система «Aliweb», существующая до сих пор. Первой полнотекстовой поисковой системой стала «WebCrawler», запущенная в 1994. В отличие от своих предшественников, она позволяла пользователям искать по любым ключевым словам на любой веб-странице, с тех пор это стало стандартом во всех основных поисковых системах. Кроме того, это был первый поисковик, о котором было известно в широких кругах. В 1994 был запущен «Lycos», разработанный в университете Карнеги Мелона.
Развитие русских поисковых машин началось в 1996 году с появлением морфологического расширения к поисковику Altavista, и запуском оригинальных российских поисковых машин Rambler и Aport. Вскоре, в 1997 году была открыта поисковая машина Яндекс.
Сегодня в мире работает несколько сотен разнообразных поисковых машин, отличающихся специализацией, возможностями и методиками поиска.
Новости
- 20/ 12/ 2005
ТОКИО, 20 дек - РИА Новости, Андрей Фесюн. Япония разработает собственную поисковую систему для Интернета в противовес набирающей популярность американской системе Google.
Как сообщил сотрудник отдела информационной политики министерства экономики, торговли и промышленности Фумихиро Кадзикава (Fumihiro Kajikawa), с этой целью будет создана исследовательская группа с участием представителей двадцати университетов и компаний по производству электроники.
"Мы не намерены конкурировать с Google или Yahoo, но думаем о создании уникальной системы исключительно для Японии", - сказал Кадзикава. По его информации, система будет предназначена прежде всего для поиска изображений, в частности, фотографий.
Представитель министерства сообщил, что первое заседание группа проведет в ближайшую пятницу, промежуточный отчет о своей деятельности представит в министерство в марте, а окончательный - в июле будущего года.
- 09.2005
Г.И. Рузайкин
Мир ПК :: Новостная лента
На пути к всеохватному информационному пространству особую остроту приобретают проблемы поиска информации в Сети. Это становится очевидным на фоне технологических успехов развития Интернета, в частности касающихся доставки информации пользователю (имеется в виду скорость передачи данных, их объем и качество). Потому-то сообщения о развитии технологий и программных продуктов для поиска информации так важны на ИТ-рынке.
Компания DVYGUN (www.dvygun.com) объявила о выпуске новой версии бесплатной персональной поисковой системы DVYGUN Smart Search 2.5.2.5 Beta, позволяющей проводить полнотекстовый поиск в массивах документов, сообщений электронной почты, мультимедийных файлов, на веб-страницах посещения и среди контактных данных, хранимых в ПК пользователя.
При этом программа DVYGUN Smart Search выполняет поиск информации (файлов) следующих типов:
- сообщения электронной почты и вложения Outlook/Outlook Express;
- файлы форматов PDF, MS Word, MS Excel, RTF, HTML и текстовые;
- данные архивов ZIP, RAR, GZIP, CAB и др.;
- изображения, музыкальные и видеофайлы;
- посещенные веб-страницы, избранные интернет-адреса браузера Internet Explorer;
- контакты адресной книги в Windows и Outlook.
Поиск данных можно вести как по всем типам, так и по избранным. Дальнейшее сужение области поиска выполняется при указании поисковых параметров. Например, для файлов ими могут быть «Имя файла», «Папка», «Размер» и «Дата изменения». Ранжирование найденных документов осуществляется по уровню соответствия поисковому запросу. Для многословных запросов учитывается контекстная близость слов, поэтому каждый найденный документ отображается в результатах поиска вместе с контекстной цитатой, что в большинстве случаев ускоряет понимание его содержания.
Для организации мгновенного поиска DVYGUN Smart Search производит первичную обработку данных с целью построения специальной базы (индекса), по которой и производится этот поиск. Вот несколько особенностей реализации этой функции в данной программе: поиск и индексация могут идти одновременно, для начала поиска не нужно дожидаться завершения индексации; обновление индекса происходит в "фоновом режиме", программа постоянно отслеживает действия пользователя, так что измененные и новые данные сразу же включаются в индекс, т.е. осуществляется актуализация результатов поиска; в случае недостаточности системных ресурсов процесс индексирования останавливается во избежание замедления работы компьютера пользователя.
Как отмечают разработчики DVYGUN Smart Search, проверка их программы на наличие и качество признаков поиска (обновление индекса на лету, подсчет релевантности результатов, настройка, скорость индексирования и поддержка морфологии русского языка) ставит ее впереди таких известных поисковиков, как Google, Yahoo, Microsoft, Copernic и Blinkx. Ни один конкурент не удовлетворяет в полном объеме требования, предъявляемые к наличию и качеству этих признаков. Программа же DVYGUN Smart Search проводит индексирование со скоростью 5 Гбайт/ч и морфологическую обработку слов русского и украинского языков. К сожалению, ни один из известных отечественных и украинских поисковиков не способен индексировать так быстро. Вместе с тем к недостаткам данной версии DVYGUN Smart Search разработчики относят малое количество обрабатываемых ею форматов файлов: поправить дело можно либо с помощью покупки соответствующих фильтров, либо путем собственной их разработки.
О развитии имеющихся поисковиков свидетельствует сообщение компании «Яндекс» (http://company.yandex.ru/news/2005/0628) о том, что новая версия программы «Яндекс.Сервер», работающая под управлением всех популярных версий ОС Windows и Unix, стала функционировать быстрее. Это расширило группу продуктов для полнотекстового поиска информации и повысило скорость обработки документов в полтора раза. Увеличено число типов обрабатываемых документов: теперь в дополнение к форматам .txt, .doc, .rtf, .html, .xml и .pdf поддерживаются .xls, .ppt и .swf. Также выросла скорость индексирования файлов с 25 до 40 Мбайт/с.
Для пользователей, которым важно управлять дизайном результатов поиска, предлагается пакет поставки новой версии данной программы по цене почти в 2 раза более низкой, чем была ранее, — всего за 170 долл. Кроме того, появились редакции этой программы для владельцев сайтов Standard+ и Professional+ с расширенными возможностями.
Как сообщили в российском представительстве компании CONVERA (www.convera.su), в будущем году ее усилия в России будут направлены на продвижение новой поисковой системы Excalibur и на разработку локализованной версии программы RetriewalWare 8.2. В ней будут реализованы такие стандартные функции, как извлечение сущностей из текста (в первом релизе к ним отнесены географические названия, имена собственные, времена, валюты, даты, номера — телефонные, кредитных карт и автомобильные, а также связи между ними), адаптеры к программным комплексам Websphere, Sharepoint portal, Documentum, новый Lotus, Windchill и Teamlink.
Осенью текущего года Excalibur появится и в России. Наиболее существенным отличием этого продукта от других подобных глобальных поисковых систем является уточнение объема релевантной информации, предлагаемой в результате поиска. Такая эффективность возможна благодаря встроенным в программу 12 млн. таксономий, с помощью которых ведется обработка информации по запросу. В процессе обработки запроса определяется его таксономическое понятие (предметная область), в результате чего вся информация делится на две группы — релевантная и нерелевантная запросу. При этом результаты запроса могут быть представлены в виде таблиц, графических изображений, текстов и информационных связей, т.е. ответ становится отображением сущности запроса и его связей в совокупности предлагаемых в результате поиска документов.
- 23 марта 1998
Новая поисковая система в Интернет
Запущен новый поисковый сервер-каталог Newman Search по информационным технологиям. Newman Search объединяет достоинства "искалок" и каталогов одновременно. Все источники, по которым производится поиск, сгруппированы по темам "Компьютерная пресса", "Новости", "Компьютерные фирмы" и т.д. Пользователи могут ограничивать область поиска соответствующими разделами, значительно уменьшая "информационный шум" и время нахождения нужного документа.
Тематика Web-сайтов в Newman Search ограничена исключительно компьютерами, Интернетом и информационными технологиями. Предпочтение отдается первоисточникам и сайтам, содержащим систематизированную информацию (документация, описания, тесты, цены, мнения, новости, пресс-релизы).
Newman Search отличает оперативная каждодневная индексация серверов - с периодом от 1 дня (для раздела "Новости") до 7 дней (для сайтов фирм компьютерного бизнеса). Тогда как в обычных поисковых системах обновления информации надо ждать месяцами.
Поиск осуществляется с учетом морфологии русского языка и компьютерной терминологии. Например , если искать "HDD" на самом деле искаться будут слова "HDD" "ВИНЧЕСТЕР" "ЖЕСТКИЙ ДИСК" "НЖМД" и т.п.
Открытая статистика переходов образует своего рода рейтинг компьютерных web-сайтов по информативности. Причем рейтинг поддерживается отдельно по каждому разделу типа "Новости" "Компьютерные фирмы" и пр.
Поисковая система Yandex
История поисковой системы Яндекс
История компании "Яндекс" началась в 1990 году с разработки поискового программного обеспечения в компании "Аркадия".
В 1993 году "Аркадия" стала подразделением компании CompTek. В 1993-1994 годы программные технологии были существенно усовершенствованы благодаря сотрудничеству с лабораторией Ю. Д. Апресяна (Институт Проблем Передачи Информации РАН).
Летом 1996 года руководство CompTek и разработчики поисковой системы пришли к выводу, что развитие самой технологии важнее и интереснее, чем создание прикладных продуктов на базе поиска. Исследования рынка показали своевременность и большие перспективы поисковых технологий.
Слово "Яndex" придумал за несколько лет до этого один из основных и старейших разработчиков поискового механизма. "Яndex" означает "Языковой index", или, если по-английски, "Yandex" - "Yet Another indexer".
Официально поисковая машина Yandex.Ru была анонсирована 23 сентября 1997 года на выставке Softool. Основными отличительными чертами Yandex.Ru на тот момент были проверка уникальности документов (исключение копий в разных кодировках), а также ключевые свойства поискового ядра Яndex, а именно: учет морфологии русского языка (в том числе и поиск по точной словоформе), поиск с учетом расстояния (в том числе в пределах абзаца, точное словосочетание), и тщательно разработанный алгоритм оценки релевантности (соответствия ответа запросу), учитывающий не только количество слов запроса, найденных в тексте, но и "контрастность" слова (его относительную частоту для данного документа), расстояние между словами, и положение слова в документе.
В ноябре 1997 года, был реализован естественно-языковый запрос. Отныне к Yandex.Ru можно обращаться просто "по-русски", задавать длинные запросы, например: "где купить компьютер", "генетически модифицированные продукты" или "коды международной телефонной связи" и получать точные ответы. Средняя длина запроса в Yandex.Ru сейчас - 2,7 слова. В 1997 году она составляла 1,2 слова, тогда пользователи поисковых машин были приучены к телеграфному стилю.
В 1998 году на Yandex.Ru появилась возможность "найти похожий документ", список найденных серверов, поиск в заданном диапазоне дат и сортировка результатов поиска по времени последнего изменения.
За 1999 год Yandex выпустил новый поисковый робот, который позволил оптимизировать и ускорить обход сайтов Рунета. Новый робот позволил предоставить пользователям новые возможности - поиск по разным зонам текста (заголовкам, ссылкам, аннотациям, адресам, подписям к картинкам), ограничение поиска на группу сайтов, поиск по ссылкам и изображениям, а также выделять документы на русском языке. Появился поиск в категориях каталога и впервые в Рунете было введено понятие "индекс цитирования".
В 2000 году образовалась компания "Яндекс". "Яндекс" был учрежден акционерами CompTek - компании, создавшей и в течение долгого времени развивавшей проект Яndex. Компания ru-Net Holdings инвестировала 5 миллионов 280 тысяч долларов и получила в новой компании долю в 35,72%. В число акционеров входят также менеджмент и ведущие разработчики поисковой системы. Генеральным директором стал Аркадий Волож.
В новообразованную компанию перешли все права на торговую марку Яndex и сайт www.yandex.ru, а также на поисковую технологию Яndex и семейство одноименных программных продуктов. Кроме того, в "Яндекс" был передан недавно стартовавший проект www.narod.ru.
Управление индексированием в поисковой системе Яндекс
Разрешения и запрещения на индексацию берутся из файла robots.txt. Яндекс поддерживает META тег robots, тег NOINDEX и нестандартное расширение robots.txt - директиву Host. Разрешения и запрещения на индексацию берутся всеми поисковыми системами из файла robots.txt, находящегося в корневом каталоге сервера. Запрет на индексацию ряда страниц может появиться, например, из желания не индексировать одинаковые документы в разных кодировках. Чем меньше сервер, тем быстрее робот его обойдет. Поэтому желательно запретить в файле robots.txt все документы, которые не имеет смысла индексировать.
Поисковая система Яндекс поддерживает нестандартное расширение robots.txt - директиву Host. Аргументом директивы Host является доменное имя (одно корректное имя хоста, не являющееся IP-адресом) с номером порта (80 по умолчанию), отделенным двоеточием. Если какой-либо сайт не указан в качестве аргумента для Host, для него подразумевается наличие директивы Disallow: /, т.е. полный запрет индексации (при наличии в группе хотя бы одной корректной директивы Host).
Это нестандартное расширение позволяет помочь поисковой системе выбрать правильное зеркало для индексирования. Фактически, в директиве Host указывается основное зеркало для сайта, при этом индексация всех других зеркал запрещена.
В целях совместимости с роботами, которые не полностью следуют стандарту robots.txt, директиву Host необходимо добавлять в группе, начинающейся с записи User-Agent, непосредственно после записей Disallow.
Поисковая система Яндекс анализирует и следует указанию META тег robots. Для запрета индексации определенных частей текста им можно пометить тегами .
Добавление страниц в поисковой системе Яндекс
Яндекс ежедневно просматривает сотни тысяч Web-страниц в поисках изменений или новых ссылок. Владельцы ресурсов могут самостоятельно добавить свой сайт, заполнив форму AddURL. Яндекс ежедневно просматривает сотни тысяч Web-страниц в поисках изменений или новых ссылок. Владельцы ресурсов могут самостоятельно добавить свой сайт, заполнив форму AddURL.
Яндекс индексирует российскую сеть, поэтому в поисковую машину вносятся сервера в доменах su, ru, am, az, by, ge, kg, kz, md, ua, uz. Остальные сервера вносятся, только если на них найден текст на русском языке, или если владельцы ресурсов убедят администрацию поисковой машины в том, что их сервер интересен пользователям русскоязычного Интернета (это обычно делается письмом на addurl@yandex.ru).
Обычно страницы появляются в поисковой базе в течение недели после их появления или изменения. Новые страницы, внесенные в базу с помощью AddURL, появятся быстрее (если они находятся в русскоязычной части сети и не требуют ручной проверки).
Поисковая система Яндекс - полнотекстовая, то есть в ее индекс попадают (и становятся доступными для поиска) только те слова, которые написаны на страницах сайтов.
В списке результатов поиска после адреса страницы выводится текст, который состоит из заголовка (тэг title), описания (тэг meta name="Description" content="") или начала документа (если этого тэга нет) и контекстов - фрагментов текста старницы, содержащих слова запроса.
Индексация в поисковой системе Яндекс
Когда Яндекс обнаруживает новую или измененную страницу, он ее индексирует. В процессе этого страница разбивается на элементы, содержание которых заносится в индекс. Когда Яндекс обнаруживает новую или измененную страницу, он ее индексирует. В процессе этого страница разбивается на элементы (текст, заголовки, подписи к картинкам, ссылки и так далее), содержание которых заносится в индекс. При этом учитываются позиции слов, то есть их положение в документе или его элементе. Сам документ в базе не хранится.
Яндекс индексирует страницы по их истинным адресам. Это значит, что, если на странице стоит redirect, робот воспримет его как ссылку на новый адрес и внесет ее в очередь на индексирование.
Как требует стандарт протокола HTTP, Яндекс, получив в заголовке ответа информацию, что данный URL является редиректом (коды 3хх), добавит в список адресов для обхода URL, на который ведет редирект. Если редирект был постоянный (код 301), либо на странице встретилась директива meta-refresh, то старый URL будет исключен из списка обхода.
Робот Яндекс хранит дату последнего обхода каждой страницы, дату ее изменения (присланную Web-сервером) и дату внесения последних изменений в базу поиска (дату индексации). Он оптимизирует обход Сети таким образом, чтобы чаще посещать наиболее изменяемые сервера. Робот Яндекс работает автоматически и обычно переиндексация происходит раз в две-три недели.
Изменения уже проиндексированных страниц робот Яндекс отслеживает самостоятельно при следующем заходе на сайт. У робота свой график работы и изменить его невозможно.
Яндекс индексирует документ полностью: текст, заголовок, подписи к картинкам, описание (description), ключевые слова и некоторую другую информацию.
Робот Яндекса обходит "динамические" страницы и относится к ним в точности так же, как и к "статическим". Поисковый робот Яндекс кроме стандартного HTML, индексирует: PDF, DOC, RTF и Flash форматы файлов.
Дубликат - это один и тот же текст, под десятком разных адресов, зависящих, например, от способа навигации по сайту. Сайты с большим числом дубликатов время от времени подвергаются безжалостной чистке.
Зеркала сайтов
Зеркало - частичная или полная копия сайта. Наличие дубликатов ресурса бывает необходимо владельцам высокопосещаемых сайтов для повышения надежности и доступности их сервиса.
Большое количество зеркал засоряет базы данных поисковых систем и приводит к появлению дубликатов в результатах поиска. Поэтому, когда робот Яндекса обнаруживает несколько зеркал сайта, он выбирает одно из них в качестве основного, остальные из индекса удаляются. По умолчанию, робот выбирает в основное зеркало исходя из собственных соображений. И обычно не то, какое хотел бы видеть владелец ресурса.
Можно принять ряд мер, позволяющих выбрать необходимый сайт в качестве основного зеркала.
Во-первых, можно удалить неосновные зеркала сайта.
Во-вторых, на всех зеркалах, кроме того, которое надо выбрать основным, разместить файл robots.txt, полностью запрещающий индексацию сайта. Либо выложить на зеркалах robots.txt с директивой Host.
В-третьих, разместить на главных страницах неосновных зеркал тег , запрещающий их индексацию и обход по ссылкам.
В-четвертых, изменить код главных страниц на неосновных зеркалах так, чтобы все (или почти все) ссылки с них вглубь сайта были абсолютными и вели на основное зеркало.
В случае реализации одного из вышеперечисленных советов основное зеркало будет автоматически изменено по мере обхода поискового робота Яндекс.
Методики работы поисковой системы Яндекс
Поисковая система Яндекс содержит в своем индексе о каждом слове текста номер документа,предложения, слова в предложении и вес каждого слова. Поисковый робот Яндекс индексирует страницы и на основании информации на них формирует поисковый индекс.
Вся эта информация используется при поиске. При каждом запросе ищутся (и получают более высокий ранг) фразы, точно совпадающие с запросом, затем предложения, содержащие все слова запроса, и т.д. Важную роль играет относительное положение слов. Так, например, если запрос из четырех слов не имеет точного ответа в базе данных, будут отранжированы выше предложения, содержащие три слова из запроса, в которых слова стоят точно в той же последовательности, что и в запросе. Это дает возможность решать типичную поисковую задачу - искать документ по "неточному цитированию".
Поисковая система Rambler
История поисковой системы Рамблер
История поисковика "Рамблер" начинается в 1991 году в городке Пущино Московской области. Именно там группой единомышленников была создана компания "Стек". Возглавил компанию "Стек" Сергей Лысаков. Занималась компания локальными сетями и подключением к Интернету.
Уже в 1996 году, Сергей Лысаков и программист Дмитрий Крюков приняли решение разработать первую русскую поисковую систему для Интернета. Дмитрий Крюков придумал название проекту - Rambler. В переводе Rambler означает "скиталец, странник, бродяга", что созвучно с принципом работы робота поисковика.
26 сентября 2006 года было зарегистрирован домен rambler.ru и уже 8 октября компания "Стек" активизировала систему. Весной 1997 года появляется "Rambler's Top100" - рейтинг-классификатор, оценивающий на основе объективных данных популярность российских ресурсов.
В июне 2003 года компания запустила новую версию поисковой машины, которая отличается от предыдущей по двум основным параметрам:
значительно увеличилась скорость поиска
благодаря новой архитектуре системы обновление поискового индекса происходит несколько раз в день.
Для тех, кто точно знает, что ищет, и не хочет тратить лишнее время, была открыта специальная лаконичная версию поиска "Рамблер" по адресу r0.ru, (или, как говорят, Арнольд).
Механизм ассоциаций от Rambler
Когда кто-либо делает ряд последовательных запросов в поисковике Рамблер, эти слова и фразы становятся связанными между собой - Rambler ассоциациями. Пользователям поисковой системы Rambler доступен механизм ассоциаций Rambler. Ассоциации Rambler - это тематически (ассоциативно) связанные запросы с исходным запросом пользователя. Когда кто-либо делает ряд последовательных запросов в поисковике Рамблер, эти слова и фразы становятся связанными между собой. И такая последовательность создает ассоциации Rambler. Фактически, это понятие "У нас также ищут".
С одной стороны, с помощью механизма ассоциаций Rambler пользователь может быстро уточнить или расширить свой запрос. С другой стороны, цепочка типичных ассоциаций выявляет недостатки исходного запроса, его неоднозначность, "размытость". В результате посетитель поисковика Rambler учится правильно спрашивать, не тратя впустую время, то есть, по сути, прибегает к помощи "коллективного разума".
Механизм ассоциаций "У нас также ищут" интересен любому, кто хочет посмотреть, о чем думают тысячи и тысячи посетителей сети. Это инструмент для поиска, равно как и источник ценной информации для лингвистов и web-мастеров.
Управление индексированием в поисковой системе Рамблер
Ограничить индексирование страниц ресурсов поисковой системой Rambler можно через robots.txt или META-тег "Robots".Робот поисковика Рамблер называется "StackRambler". Именно он скачивает документы, выставленные в Интернет, находит в них ссылки на другие документы, скачивает вновь и т.д. Робот StackRambler анализирует файл robots.txt и ограничивает сканирование ресурса, согласно его указаний. Через robots.txt можно запретить доступ к определенным каталогам и/или файлам.
Ограничить сканирование страниц ресурса роботом поисковой системы Рамблер так же можно через META-тег "Robots". Тег управляет индексацией конкретной web-страницы. При этом роботам можно запретить не только индексацию самого документа, но и проход по имеющимся в нем ссылкам.
Добавление страниц в поисковой системе Рамблер
Робот Рамблера обходит Сеть по ссылкам и таким образом находит новые ресурсы. Можно заполнить регистрационную анкету. Робот Рамблера самостоятельно посещает только сайты, расположенные в национальных доменах .ru, .su, .ua, .by, .kz, .kg, .uz, .ge. Если сайт расположен в одной из других доменных зон (например, в .com, .net или .org, либо в других национальных доменах), по умолчанию роботы Рамблера не будут посещать страницы таких ресурсов. Для добавления таких ресурсов, представляющих интерес для русскоязычных пользователей, в число сканируемых необходимо обратиться к администратору поисковой системы Рамблер.
Робот Рамблера обходит Сеть по ссылкам и таким образом находит новые ресурсы для индексирования. Также можно заполнить регистрационную анкету в поисковой системе Rambler. Поля этой анкеты - "Название сайта" и "Описание" не используются для поиска. Они предназначены только для прочтения редакторами и используются во внутренних базах данных Rambler.
Робот сканирует страницы сайта в течение суток с момента регистрации (или нахождения ресурса). При этом он сразу же обходит сайт на некоторую глубину (сканирует страницы, на которые ссылается зарегистрированная страница). Скачанные роботом страницы появляются в поисковой базе с некоторой задержкой. Переиндексация полученных документов производится с интервалом приблизительно в две недели.
Индексация в поисковой системе Рамблер
При индексации поисковой системой Рамблер учитывается лишь та информация, которую пользователь может увидеть на странице. Базовые понятия и ключевые для сайта слова целесообразно включать в следующие HTML-теги (в порядке значимости):
title
h1...h4
b, strong, u
Чем чаще слово встречается в этих полях, тем более вероятно, что поисковая система Rambler выдаст ссылку на этот документ ближе к началу списка результатов поиска.
Максимальный размер документа для роботов Рамблера составляет 200 килобайт. Документы большего размера усекаются до указанной величины.
Программа индексирования обрабатывает переадресацию (редиректы), но только в том случае, если перенаправление выполняется в домен .ru или в домены некоторых стран СНГ.
Рамблер обрабатывает все "динамические" страницы с именами вида *.asp*, *.php*, *.pl*, */cgi-bin/* и т. п. для посещаемых сайтов (по данным top100), а также сайтов, содержащих уникальную информацию, полезную пользователям поисковой машины. Для остальных сайтов обрабатывается только часть таких страниц.
Фрагменты HTML, размеченные тегами , Рамблером не индексируются.
Поисковая машина Рамблер умеет извлекать ссылки из объектов flash и потому может обрабатывать сайты, построенные на флэш-технологии. Однако сами тексты flash-объектов пока не индексируются.
При индексации учитывается лишь та информация, которую пользователь может увидеть на странице.
Скрытые поля и все другие поля
Поиск учитывает данные Top100. Специальный робот Рамблера два раза в день добавляет в базу поисковой машины новые страницы со всех сайтов, которые участвуют в рейтинге Top100 и разместили счетчик на своих страницах. После изменения информации в рейтинге Top100 ее обновление в поисковой системе происходит в течение одного-двух дней. Если сайт зарегистрирован в Top100, он будет находиться по некоторым запросам, даже если информация была удалена из индексной базы.
При поиске учитывается информация, полученная из рейтинга Rambler's Top100, если сайт в нем зарегистрирован. Число показывает, когда была получена эта информация. Информация по Top100 обновляется практически каждый день.
Поисковая система Aport
История поисковой системы Апорт
Официальная презентация "Апорт" состоялась 11 ноября 1997 года. К тому времени в его базе был проиндексирован первый миллион документов, расположенных на 10 тысячах серверов. Создателем поисковой системы Апорт является компания "Агама" - разработчик программного обеспечения для платформ Windows. Надо отметить, что Апорт создавался и продолжает работать под управлением ОС Windows (в отличие от большинства поисковых систем). Лингвистические разработки "Агамы" использовались при создании поисковой машины Апорт, в которой на момент ее создания, учитывалась морфология слов и по желанию клиента выполнялась проверка орфографии запроса.
Впервые поисковая система "Апорт" была продемонстрирована в феврале 1996 года на пресс-конференции "Агамы" по поводу открытия "Русского клуба". Первоначально поисковая система Апорт выполняла поиск только по сайту russia.agama.com.
Официальная презентация поисковой системы "Апорт" состоялась только 11 ноября 1997 года. К тому времени в базе Апорт был проиндексирован первый миллион документов, расположенных на 10 тысячах серверов.
Важнейшими особенностями первой версии "Апорта" являлся перевод запроса и результатов поиска на английский язык и обратно, а также реконструкция всех проидексированных страниц из собственной базы.
В ноябре 1998 года поисковая система "Апорт" была приобретена гражданином Израиля Джозефом Авчуком (с сохранением торговых марок "Апорт" и "Агама"). Реальная сумма сделки составила 55 тысяч долларов.
В октябре 1999 года на компьютерных выставках по обе стороны океана была представлена принципиально новая поисковая система "Апорт 2000", полностью интегрированная с AtRus (ныне "Каталог-Апорт").
"Апорт 2000" стал первым русским поисковиком, построенным на основе выдачи результатов по отдельно взятым сайтам. Для разделения ресурсов на сайты используется информация, которую "Апорту" предоставляет каталог AtRus или сведения, введенные в "Апорт" владельцами ресурсов.
"Апорт 2000" стал первой российской поисковой системой, реализовавший две базовых технологии американской поисковой машины Google.
Учет "ранга страницы" (Page Rank), который характеризует ее популярность. Значение ранга вычисляется по количеству ссылок на ресурс из внешнего Интернета. Вес ссылки с популярного сайта выше, чем вес ссылки с менее популярного; ссылки, включающие слова запроса, имеют больший вес, чем, скажем, слово "здесь".
Обработка запроса с анализом HTML тегов страниц. Например, текст между тегами h2 имеет больший приоритет, чем между тегами h6.
В "Апорт 2000" также учитывалось вхождение слов запроса в URL. Среди недокументированных особенностей - больший приоритет сайтам, получившим высшую и элитную лигу в каталоге AtRus.
И, наконец, еще одно первенство "Апорт" - использование платной нулевой строки в выдаче (кстати, "Апорт" первым среди наших поисковиков начал покупать такой сервис у AltaVista, которая за небольшую плату выдавала его ссылку первой при запросе "Russian Search"). Однако в "Апорте" нельзя купить не нулевое, а просто более высокое место для своего сайта в результатах поиска.
Организация масштабируемости в архитектуре "Апорт 2000" такова, что можно дробить поисковую базу "Апорта" на несколько отдельных баз, каждый маленький "Апорт" работает на своем компьютере. "Апорт 2000" считает, что весь Интернет поделен на фрагменты. После проведения поиска по этим фрагментам, пользователю интегрируется и выдается общий ответ. Добавлять новые маленькие "апортики" можно путем не очень сложной процедуры. В случаях аварий отдельных машин выдаются несколько отличные от штатных интегральные результаты, что можно время от времени наблюдать.
31 июля 2000 года Golden Telecom купил семейство интернет-проектов "Агама", включающее "Апорт" и AtRus, для включения в "Россию-он-лайн" и околоконтентные проекты.
В мае 2001 года окончательно завершилась сделка по смене хозяина "Апорт" самого "Golden Telecom", новым владельцем стал "Альфа-Банк". NASDAQ к тому времени переживал бурный спад и шансов перепродать Интернет проекты за приемлемую сумму не было. Это обусловило решение новых хозяев "Golden Telecom" минимизировать расходы на поддержку дорогостоящих Интернет проектов.
Управление индексированием в поисковой системе Апорт
При просмотре содержимого сервера для индексирования Апорт проверяет файл robots.txt и поддерживает мета-теги Robots. При просмотре содержимого сервера для индексирования Апорт проверяет файл robots.txt. Таким образом, можно ограничить "деятельность" Апорта на сервере. Поисковый робот Апорт имеет имя Aport. Именно это имя может быть использовано для ограничения индексирования через robots.txt.
Также поисковая система Апорт поддерживаются мета-теги Robots, позволяющие, установить правила поведения робота на индивидуальной странице сайта и в случае, если нет возможности изменять файл robots.txt на сервере.
Добавление страниц в поисковой системе Апорт
Регистрация сайта в Апорте производится со страницы Добавить URL. Добавлять следует только корень сайта. Регистрация сайта в Апорте производится со страницы http://catalog.aport.ru/rus/reg/add.ple. Эта страница доступна по ссылке Добавить URL почти с любой страницы Апорта. Добавлять следует только корень сайта, остальные страницы будут найдены Апортом по ссылкам.
Апорт является поисковой системой по российскому Интернету, поэтому добавлять в нее можно русскоязычные сайты, а также сайты имеющие непосредственное отношение к российскому Интернету. В случае отказа в автоматическом добавлении сайта (например, если поисковый робот не найдет на его корневой странице русскоязычного текста) можно обратиться с просьбой о добавлении сайта по e-mail: addurl@rol.ru
Индексация ресурсов поисковой системой Апорт
Апорт - полнотекстовая поисковая система. Это означает, что она индексирует все слова, которые бы увидел на экране человек, просматривая конкретную страницу сервера. Апорт периодически проверяет имеющиеся в его базе сайты и приводит свою базу в соответствие с произошедшими там изменениями. Период проверки в значительной степени зависит от конкретного сайта (учитывается его популярность, динамичность обновления по данным собранным апортом при предыдущих заходах на сайт и ряд других факторов).
С момента добавления сайта в поисковую систему Апорт до момента его появления в поисковой базе проходит от двух-трех дней до двух недель. В отдельных случаях, (например, в случае нестабильной связи с добавленным сайтом), это время может оказаться несколько больше.
Апорт индексирует все статические документы (в Url которых не встречается символ "?"), найденные его поисковым роботом по ссылкам на сайте. Это правило может не соблюдаться для больших по объему сайтов, а также для сайтов, замеченных в применения поискового спама.
Документы, содержащие в Url символ "?", индексируются поисковой системой Апорт выборочно. При этом используется квотирование количества таких документов для каждого сайта. Размер квоты вычисляется автоматически в зависимости от ряда условий, в частности от индекса цитируемости сайта, и может, в частности, быть для некоторых сайтов нулевым.
Необходимо учитывать, что полная индексация сайта может происходить постепенно, а также то что содержание базы является прерогативой поисковой системы и каких-либо гарантий по индексации (а также сохранению в индексе уже проиндексированных документов) Апорт не дает.
Апорт - полнотекстовая поисковая система. Это означает, что она индексирует все слова, которые бы увидел на экране человек, просматривая конкретную страницу сервера. В результате любое слово из текста документов может служить критерием последующего поиска.
Для документов HTML кроме основного текста документа индексируются также: заголовок документа (TITLE), ключевые слова (META KEYWORDS), описания страниц (META DESCRIPTION) и подписи к картинкам (ALT). Кроме того, Апорт индексирует как принадлежащие документу, тексты гиперссылок на этот документ с других страниц, находящихся, как внутри сайта, так и за его пределами, а также составленные (или проверенные) редакторами описания сайтов из каталога Апорт.
Поисковая система Google

Данная поисковая система со временем становится все лучше и популярнее, но она уступает вышеперечисленным поисковым системам. По данным опросов, данным Google обеспечивает около 10% всех поисковых запросов Рунета. На регистрацию Google принимает сайты любого домена, то есть он не ограничивается только зоной ru. Это, безусловно, очень большое преимущество перед конкурентами (в России). Но Google больше не имеет никаких преимуществ и даже не может выдавать в результатах поиска слова, которые являются синонимами запроса. То есть, если мы задаем в Google поисковый запрос "анекдот", то Google будет искать на сайтах именно это слово, в то время как Яндекс, Рамблер и Апорт помимо этого слова будут учитывать на сайтах и слова-синонимы, например, "анекдоты", а Google этого сделать не может.
Зарубежные поисковые системы
- AOL Search
- Achla
- AltaVista
- AltaVista (Digital)
- Austria NetGuide
- AustroNaut
- Alltheweb
- AntiSearch
- Ask Jeeves
- AskAlex
- Anzwers
- AusIndex
- AustriA-WWW
- Baku Pages
- Brit Index
- Compnet
- Copernic
- Cyber411
- Direct Hit
- Daypop.com
- Excite
- England Online
- Freeality
- FTP Search
- GBP Great British Pages
- HotBot
- HandiLinks
- Infoseek
- InfoMarket
- Infomine
- InterSearch Austria
- Interview
- Inktomi
- Inforia
- IWon
- GoTo
- Guide.at
- LookSmart
- Lycos
- Light Search
- Libanis.com
- Magellan
- MaxiSearch
- MSN Search
- MAIR
- Mixcat.com
- Meta-ukraine.com
- Metacrawler
- Northern Light
- Netscape Search
- Open Directory
- Open Text
- Qango
- Raging Search
- RealNames
- Snap
- Search.com
- SeachUk
- Search.lv
- Search.iwon.com
- Submitit.bcentral.com
- Superpromo.com
- Search.escapeartist.com
- Surfgopher.com
- Slider.com
- Uk Index
- UkDirectory
- UkMax
- Whatuseek.com
- WebCrawler
- Web Wombat
- Yahoo
- 2kcity.com
Архитектура метапоисковых систем
Введение
В данной статье на примере метапоисковой системы MetaPing рассматривается архитектура метапоисковых систем и основные принципы их работы и построения.
Что такое метапоисковая система?
Ни для кого не секрет, что всемирная сеть Интернет, содержащая постоянно растущий огромный объем динамически изменяющейся информации, развивается небывало бурными темпами. Для того, чтобы как-то упорядочить этот непрерывный поток данных, а самое главное, дать возможность пользователям Сети находить нужную информацию, были созданы специальные поисковые системы. Каждая такая система имеет индекс, несущий служебную информацию о содержимом проиндексированных документов, где каждому слову текста соответствует частота его употребления и координаты данного слова в тексте.
Каждая поисковая система имеет только свое собственное, ограниченное ее ресурсами, множество документов, которые доступны для поиска. Ни одна из подобных систем не сможет охватить всех ресурсов Интернет, поэтому в любой момент может возникнуть ситуация, когда информационные потребности пользователя не смогут быть удовлетворены. Как правило, в этом случае пользователь переходит на другую поисковую систему и пытается искать то, что ему нужно, там.
Для решения данной проблемы и расширения возможности поиска, были созданы системы, названные метапоисковыми. Они не имеют собственных поисковых баз данных, не содержат никаких индексов и при поиске используют ресурсы множества поисковых систем. За счет этого полнота поиска в таких системах максимальна и вероятность нахождения нужной информации очень высока.
Принципы работы метапоисковых систем
При проектировании метапоисковой системы нужно решить ряд проблем.
Прежде всего, из полученного от поисковых систем множества документов необходимо выделить наиболее релевантные, то есть соответствующие запросу пользователя. Как правило, создатели метапоисковых систем не совсем оправданно надеются, что поисковые системы, которые они используют, возвращают релевантные результаты поиска, и слишком полагаются на позицию, на которой в данной поисковой системе находится документ.
Этот стандартный подход представлен на рис. 1. В таких системах анализ полученных описаний документов не производится, что может поставить нерелевантные документы, идущие первыми в одной поисковой системе, выше релевантных в другой, чем существенно понизить качество самого поиска. Этот принцип оказался хорошим при создании автором анализатора позиции сайта в поисковых системах, но в целом для систем метапоиска оказался неудовлетворительным.
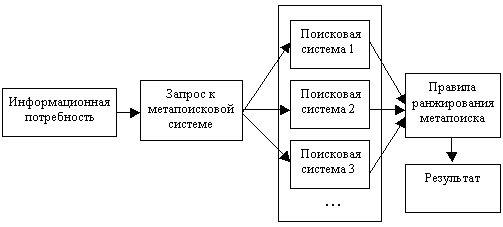
Рис.1 Стандартная метапоисковая система
При разработке следующего поколения метапоисковых систем были учтены недостатки, присущие стандартным метапоисковым системам. Были созданы системы с возможностью выбора тех поисковых машин, в которых, по мнению пользователя, он с большей вероятностью может найти то, что ему нужно (рис. 2)
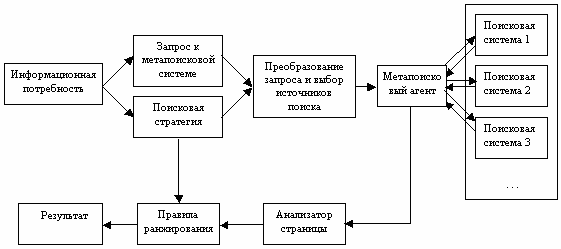
Рис. 2. Следующее поколение метапоисковых систем
Кроме этого, такой подход позволяет уменьшить используемые вычислительные ресурсы метапоискового сервера, не перегружая его слишком большим объемом ненужной информации и серьезно сэкономить трафик. Здесь нужно отметить, что в любой системе метапоиска наиболее узким местом в основном является пропускная способность канала передачи данных, так как обработка страниц с результатами поиска, полученными от нескольких десятков поисковых серверов не является слишком трудоемкой операцией, потому что затраты времени на обработку информации на порядки меньше времени прихода страниц, запрошенных у поисковых серверов.
Как пример систем, имеющих подобную организацию, можно назвать Profusion, Ixquick, SavvySearch, MetaPing.
Как же все это работает?
Ниже будет описан принцип работы метапоисковой системы MetaPing, разработанной автором этой статьи, однако общие принципы будут верны и для остальных систем этого класса (см. рис. 2).
Начнем со стартовой страницы данной метапоисковой системы. Обычно интерфейс такой системы предельно упрощен и сразу же позволяет понять, что, где и как здесь можно искать. В нашем случае (MetaPing) поиск возможен по трем областям поиска: по России, по Украине и по всему миру, при этом имеется возможность искать все, отметив поиск по интернету, или сузить область поиска и искать конкретно объявления, новости, файлы и рефераты (рис. 3).
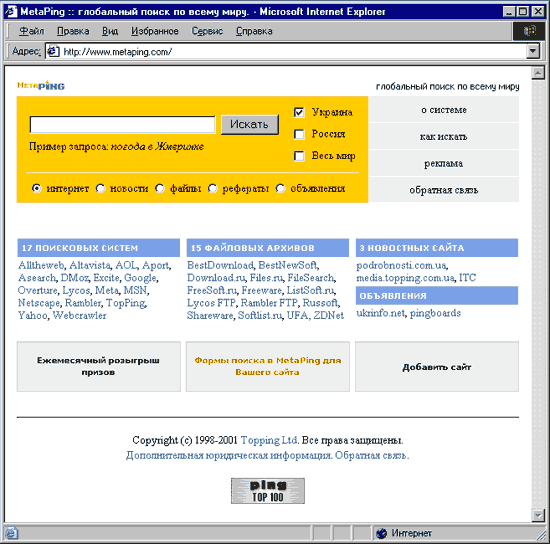
Рис.3 Стартовая страница MetaPing
Пользователь выбирает, скажем, поиск по России, и вводит, например, такой запрос: "лучшие поисковые системы" (рис. 4).
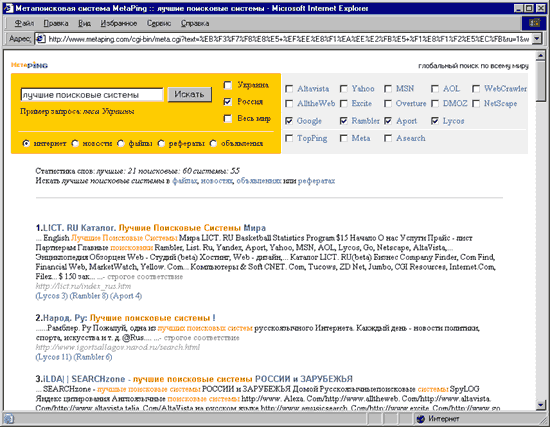
Рис. 4 Страница MetaPing с результатами поиска
После этого запрос ретранслируется указанным российским поисковым системам (в нашем случае это Рамблер, Апорт, Lycos и Google). Следует отметить, что Google, хотя и не является российской поисковой системой, в настоящее время успешно с ними конкурирует как по полноте баз, так и по качеству поиска, и именно поэтому он здесь оказался. Кстати, внимательный читатель наверняка отметил отсутствие самой крупной российской поисковой системы Яндекс. На момент запуска MetaPing Яндекс тоже здесь тоже присутствовал, но после известного скандала его пришлось убрать.
Для передачи запроса к поисковой системе используется специальный метапоисковый агент, который отвечает не только за процесс ретрансляции запроса и приема страниц, но и за то, чтобы запрос был передан в правильной кодировке, принятой в каждой из выбранных поисковых систем, иначе будет получен совершено другой набор описаний документов или не будет получен вовсе, что негативно скажется на качестве поиска.
После обработки полученного запроса каждая система возвращает метапоисковому агенту множество описаний и ссылок на документы, которые считает релевантными данному запросу.
Как среди этого множества выбрать именно то, что нужно пользователю?
В начале этой статьи уже упоминался стандартный подход, который используется большинством систем метапоиска и состоит в том, чтобы просто расположить полученные ссылки по порядку их следования в результатах поиска каждой из поисковых систем. При этом, если в разных поисковых системах был найден один и тот же сайт, то ценность его для пользователя, естественно, существенно повышается.
Подход, безусловно, правильный, но что делать в том случае, если одна система, к примеру, индексирует динамически генерирующиеся страницы, а другая нет? У них различные множества проиндексированных документов, различная полнота баз, следовательно, запрошенная пользователем информация может быть найдена в одной системе и может быть не найдена в другой. В этом случае пользователь может получить несколько действительно релевантных ссылок от одной системы, которые будут перемешаны с абсолютно нерелевантными из другой (например, в случае, когда фраза целиком не найдена, поиск идет по одному из ключевых слов запроса). В результате, пользователю вручную приходится отбирать релевантные ссылки и велика вероятность того, что покопавшись в подобном "винегрете", он попросту уйдет и уже никогда не вернется.
Есть ли какой-либо способ решить эту проблему? Конечно есть. Нужно с полученным от поисковых систем множеством описаний документов сделать то же, что делают они сами с этими документами, то есть определить частоты ключевых слов в каждом заголовке и описании и попытаться самостоятельно определить рейтинг каждого из них.
Именно по такому принципу построена метапоисковая система MetaPing, где реализован смешанный алгоритм обработки информации. Автором были разработаны специальные программы для анализа полученных данных, благодаря которым на первом этапе происходит ранжирование множества описаний полученных документов, на втором ранг дополнительно корректируется согласно месту, на котором находится документ, и общему количеству документов, найденных по запросу (это позволяет оценить полноту поисковых баз конкретной системы).
Подобная обработка позволяет не только убирать документы, в описании которых вообще нет ключевых слов как потенциально нерелевантные запросу, но и находить строгое соответствие в том случае, если все ключевые слова встречаются в описании документа полностью, что неизмеримо повышает качество и точность поиска.
Метапоисковые системы Inforian Quest 98 и Copernic 98
 Inforian Quest 98 (IQ - удачная аббревиатура, не правда ли?). Продукт компании Inforian, плод коллективных усилий японских, китайских и американских программистов.
Inforian Quest 98 (IQ - удачная аббревиатура, не правда ли?). Продукт компании Inforian, плод коллективных усилий японских, китайских и американских программистов.
Вес около 3.5Mb, требует до 5Mb свободного дискового пространства. Стоимость полной версии 25 долларов США, shareware - 1 месяц.
Использует два стиля: Essence, для опытных пользователей, и Wizard, для начинающих. Оба стиля отличает чрезвычайная простота. Inforian Quest 98 позволяет осуществлять быстрый метапоиск по семи наиболее популярным серверам (Yahoo!, Altavista, InfoSeek, Excite, HotBot, OpenText, WebCrawler), обращаться дополнительно почти к 200 поисковым серверам Америки, Европы, Японии и Китая, плюс производить опрос внутри этих баз данных по семи тематическим разделам Искусство и Развлечения (Arts & Entertainment), Новости и Бизнес (News & Business), Компьютеры и Интернет (Computers & Internet), Программное обеспечение и файлы (Software & FTP), Группы новостей (Usenet (Discussion Group)), Научные технологии (Technology), Адреса и телефоны (Yellow Pages). Есть надежда на включение в ближайшее время в список "обыскиваемых" серверов израильских и российских клиентов.
В зависимости от степени Вашего долготерпения рекомендуется настроить время ожидания (wait for...) выдачи результатов поиска (минимум - 1 секунда, максимум - почти 4 месяца, рекомендовано - 1-2 минуты) и указать предельное количество сообщений от каждого найденного сайта (links per site) (по умолчанию, 10). Если Вы хотите получать исключительно свежую информацию и готовы ради этого немного пожертвовать скоростью поиска, - откажитесь от использования proxy-сервера. При желании можно легко изменить язык интерфейса с английского на немецкий, французский или испанский, если же Ваш компьютер не только собран, но и начинён программным обеспечением дальневосточными умельцами, - можно попробовать японский или китайский интерфейс. Поражает великолепно исполненный "подсказчик", перейти к которому можно, нажав на клавиатуре клавишу F1 или по сценарию Help --> Help Topics.
 Не меньшей популярностью на сегодняшний день пользуется и Copernic 98 - метапоисковая система от ATC (Agents Technologies Corporation). Главное достоинство программы - отсутствие необходимости платить за основную версию, время пользования не ограниченно. Данная программа превосходит своего конкурента как лёгкостью (около 2.5Mb), так и объёмом опрашиваемого при поиске информационного пространства. В обойму основных поисковых серверов добавлены, по сравнению с конкурентом, NetFind, LookSmart, Lycos, Magellan, хотя и забыт весьма перспективный OpenText. Примечательно, что разыскивая с помощью Copernic 98 кого-либо из Ваших знакомых в Сети, Вы используете не только ресурсы традиционных Who Where?, BigFoot, Four11, но и базу данных "героя нынешнего сезона", компании Mirabilis. Тематическим каталогом, содержащим около 20 разделов и аккумулирующим информацию свыше 100 поисковых систем, можно пользоваться, если Вы избрали версию "plus" (30 дней бесплатно, понравится, доплатите 30 долларов США). На сегодняшний день в разработке находится так называемый Channel Development Kit, который позволит Вам самостоятельно добавлять к списку любую поисковую систему. Если при этом Copernic не будет считать ошибочной поисковую фразу на русском или иврите, - в нашей стране этому направлению обеспечена немалая популярность.
Не меньшей популярностью на сегодняшний день пользуется и Copernic 98 - метапоисковая система от ATC (Agents Technologies Corporation). Главное достоинство программы - отсутствие необходимости платить за основную версию, время пользования не ограниченно. Данная программа превосходит своего конкурента как лёгкостью (около 2.5Mb), так и объёмом опрашиваемого при поиске информационного пространства. В обойму основных поисковых серверов добавлены, по сравнению с конкурентом, NetFind, LookSmart, Lycos, Magellan, хотя и забыт весьма перспективный OpenText. Примечательно, что разыскивая с помощью Copernic 98 кого-либо из Ваших знакомых в Сети, Вы используете не только ресурсы традиционных Who Where?, BigFoot, Four11, но и базу данных "героя нынешнего сезона", компании Mirabilis. Тематическим каталогом, содержащим около 20 разделов и аккумулирующим информацию свыше 100 поисковых систем, можно пользоваться, если Вы избрали версию "plus" (30 дней бесплатно, понравится, доплатите 30 долларов США). На сегодняшний день в разработке находится так называемый Channel Development Kit, который позволит Вам самостоятельно добавлять к списку любую поисковую систему. Если при этом Copernic не будет считать ошибочной поисковую фразу на русском или иврите, - в нашей стране этому направлению обеспечена немалая популярность.
При каждой поисковой операции Вы можете изменять максимальные значения общего числа результатов поиска и количества сообщений в отдельном поисковом канале (Search --> New --> Parameters --> Custom Search). Можно подключить к работе proxy-сервер (View --> Options --> Connection --> Proxies).